From the first days I have worked as software engineer, I always hear the same request by many sides:
“We want to have everything configurable, we want to change everything on runtime and we want to have a visual tool to apply all this logic in order to non-developer people use and configure our application.”
I like this generic scope too, but as we all know software systems are not so adaptable and customer requests are not stable.
In previous years, we have built such configurable applications (not 100% configurable) using traditional frameworks/techniques (JMX, distributed cache, Spring or JEE and more).
In recent years, there is an additional concept that have to be included in our architecture, this is the concept of Big Data (or 3V or 4V or whatever words fit better). This new concept deprecates various solutions or workarounds that we were familiar and applied in old 3 tiers applications.
The funny thing is that many times I find myself in the same position as 10 years back. This is the rule on software development, it never ends and so personal excellence and new adventures never end too 🙂
The main problem remains the same, how to build a configurable ETL distributed application.
For this reason, I have built a mini adaptable solution that might be helpful in many use cases.
I have used 3 common tools in big data world: Java, Apache Storm and Kite SDK Morplines.
Java as the main programming language, Apache Storm as the distributed streaming processing engine and Kite SDK Morphlines as the configurable ETL engine.
Kite SDK Morplines
Copied from its description: Morphlines is an open source framework that reduces the time and efforts necessary to build and change Hadoop ETL stream processing applications that extract, transform and load data into Apache Solr, HBase, HDFS, Enterprise Data Warehouses, or Analytic Online Dashboards. A morphline is a rich configuration file that makes it easy to define a transformation chain that consumes any kind of data from any kind of data source, processes the data and loads the results into a Hadoop component. It replaces Java programming with simple configuration steps, and correspondingly reduces the cost and integration effort associated with developing and maintaining custom ETL projects.
Additional to builtin commands, you can easily implement your own Command and use it in your morphline configuration file.
Sample Morphline configuration that read a JSON string, parse it and then just log a particular JSON element:
morphlines : [{
id : json_terminal_log
importCommands : ["org.kitesdk.**"]
commands : [
# read the JSON blob
{ readJson: {} }
# extract JSON objects into head fields
{ extractJsonPaths {
flatten: true
paths: {
name: /name
age: /age
}
} }
# log data
{ logInfo {
format : "name: {}, record: {}"
args : ["@{name}", "@{}"]
}}
]
}]
Storm Morphlines Bolt
In order to use Morphlines inside Storm, I have implemented a custom MorphlinesBolt. The main responsibilities of this Bolt are:
- Initialize Morphlines handler via a configuration file
- Initialize mapping instructions:
a) from Tuple to Morphline input and
b) from Morphline output to new output Tuple
- Process each incoming event using the already initialized Morplines context
- If Bolt is not Terminal, then using the provided Mapper (type “b”), emit a new Tuple using the output of Morphline execution
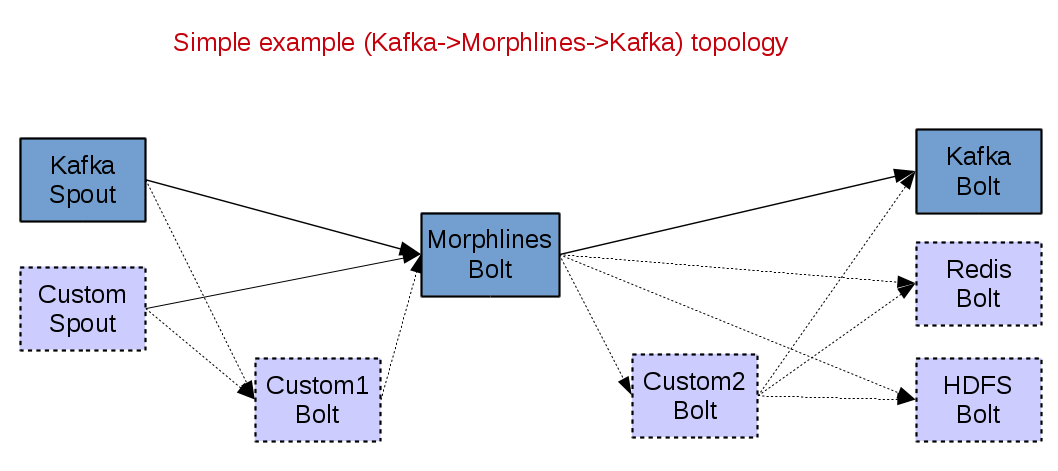
Simple Configurable ETL topologies
In order to test custom MorphlinesBolt, I have written 2 simple tests. In these tests you can see how MorphlinesBolt is initialized and then the result of each execution. As input, I have used a custom Spout (RandomJsonTestSpout) that just emit new JSON strings every 100ms (configurable).
DummyJsonTerminalLogTopology
A simple topology that configure Morphline context via a configuration file and the execute Morphline handler for each incoming Tuple. On this topology, MorphlinesBolt is configured as terminal bolt, which means that for each input Tuple does not emit new Tuple.
public class DummyJsonTerminalLogTopology {
public static void main(String[] args) throws Exception {
Config config = new Config();
RandomJsonTestSpout spout = new RandomJsonTestSpout().withComplexJson(false);
String2ByteArrayTupleMapper tuppleMapper = new String2ByteArrayTupleMapper();
tuppleMapper.configure(CmnStormCons.TUPLE_FIELD_MSG);
MorphlinesBolt morphBolt = new MorphlinesBolt()
.withTupleMapper(tuppleMapper)
.withMorphlineId("json_terminal_log")
.withMorphlineConfFile("target/test-classes/morphline_confs/json_terminal_log.conf");
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("WORD_SPOUT", spout, 1);
builder.setBolt("MORPH_BOLT", morphBolt, 1).shuffleGrouping("WORD_SPOUT");
if (args.length == 0) {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("MyDummyJsonTerminalLogTopology", config, builder.createTopology());
Thread.sleep(10000);
cluster.killTopology("MyDummyJsonTerminalLogTopology");
cluster.shutdown();
System.exit(0);
} else if (args.length == 1) {
StormSubmitter.submitTopology(args[0], config, builder.createTopology());
} else {
System.out.println("Usage: DummyJsonTerminalLogTopology <topology_name>");
}
}
}
DummyJson2StringTopology
A simple topology that configure Morphline context via a configuration file and the execute Morphline handler for each incoming Tuple. On this topology, MorphlinesBolt is configured as normal bolt, which means that for each input Tuple it emits a new Tuple.
public class DummyJson2StringTopology {
public static void main(String[] args) throws Exception {
Config config = new Config();
RandomJsonTestSpout spout = new RandomJsonTestSpout().withComplexJson(false);
String2ByteArrayTupleMapper tuppleMapper = new String2ByteArrayTupleMapper();
tuppleMapper.configure(CmnStormCons.TUPLE_FIELD_MSG);
MorphlinesBolt morphBolt = new MorphlinesBolt()
.withTupleMapper(tuppleMapper)
.withMorphlineId("json2string")
.withMorphlineConfFile("target/test-classes/morphline_confs/json2string.conf")
//.withOutputProcessors(Arrays.asList(resultRecordHandlers));
.withOutputFields(CmnStormCons.TUPLE_FIELD_MSG)
.withRecordMapper(RecordHandlerFactory.genDefaultRecordHandler(String.class, new JsonNode2StringResultMapper()));
LoggingBolt printBolt = new LoggingBolt().withFields(CmnStormCons.TUPLE_FIELD_MSG);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("WORD_SPOUT", spout, 1);
builder.setBolt("MORPH_BOLT", morphBolt, 1).shuffleGrouping("WORD_SPOUT");
builder.setBolt("PRINT_BOLT", printBolt, 1).shuffleGrouping("MORPH_BOLT");
if (args.length == 0) {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("MyDummyJson2StringTopology", config, builder.createTopology());
Thread.sleep(10000);
cluster.killTopology("MyDummyJson2StringTopology");
cluster.shutdown();
System.exit(0);
} else if (args.length == 1) {
StormSubmitter.submitTopology(args[0], config, builder.createTopology());
} else {
System.out.println("Usage: DummyJson2StringTopology <topology_name>");
}
}
}
Final thoughts
MorphlinesBolt can be used as part of any configurable ETL “solution” (as single processing Bolt, as Terminal Bolt, as part of complex pipeline, etc.).

Source code is provided as a maven module (sv-etl-storm-morphlines) within my collection of sample projects in github.
A great combination would be to use MorphlinesBolt with Flux. This might give you a fully configurable ETL topology!!!
I have not added as option yet, in order to keep it with less dependencies (I may added with scope “test”).
This module is not final and I will try to improve it, so you many find various bugs in this first implementation.
For any additional thoughts or clarifications, then please write a comment 🙂
This is my first post in 2016! I hope you good health and with better thoughts and actions. The first virtues/values of everything is the human and the respect to the environment we all live (society, earth, animals, plants, etc.). All the others are secondary priorities and should not ruin what is implied by first priorities. Keep your most important virtues always in your mind and consider them in any action or thought you do.
Regards,
Adrianos Dadis.
—
Real Democracy requires Free Software