Real Time Sentiment Analysis refers to processing streams of natural language text (or voice) in order to extract subjective information. The trivial use case is for building a recommendation engine or for finding social media trends.
I have selected Apache Storm as real time processing engine. Storm is very robust (we are using it on production) and very easy to implement custom logic on top of it.
I have written a very simple project (source code) that performs sentiment analysis on real time (using random sentences as input data). The scope is to get random sentences as input and then perform some sentiment analysis. Finally decide if current sentence has a positive or negative score and persist results.
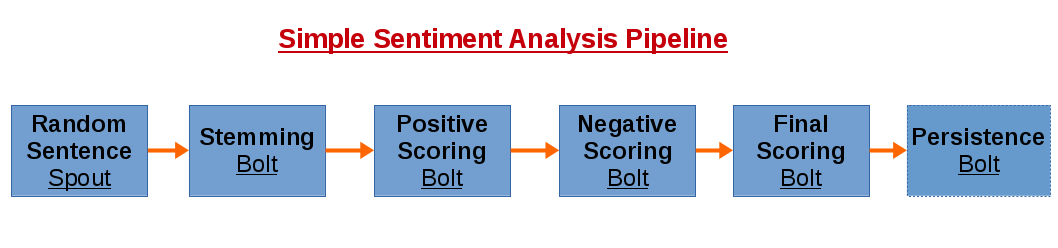
Implementation logic is the following:
- (Dummy Spout) Feed pipeline with random sentences.
- (Stemming Bolt) Stem any word that is useless for scoring. Create a new sentence that does not contain useless words (e.g articles) and pass it to next component.
- (Positive Scoring Bolt) Get stemmed (modified) sentence and provides a positive score.
- (Negative Scoring Bolt) Get stemmed sentence and provides a negative score.
- (Final Scoring Bolt) Compare positive and negative score and decide if this sentence is positive or negative.
- (Persistence Bolt) Persist processed data:
original sentence, modified sentence and final, positive and negative scores
As persistent store, I have selected Apache HBase (just for reference), where it stores events in batch mode. Batch persistence is triggered every 1 second (configurable), using an internal triggering mechanism of Storm (Tick Tuple). Additional to HBase, we can easily use Redis, Cassandra, MongoDB or Elasticsearch (all these are valid for this use case).
Each of the Stemming and Scoring Bolts are using a dummy in memory database that contains all relative words that can use in order to score/stem each sentence.
In order to run this example in single node or cluster, you can use Storm project Flux. The whole topology pipeline is defined using a single configuration file (topology.yaml).
Example run:
Local execution: storm jar target/sentiment-analysis-storm-0.0.1-SNAPSHOT.jar org.apache.storm.flux.Flux --local src/test/resources/flux/topology.yaml -s 10000 Cluster execution: storm jar target/sentiment-analysis-storm-0.0.1-SNAPSHOT.jar org.apache.storm.flux.Flux --remote src/test/resources/flux/topology.yaml --c nimbus.host=localhost
Alternatevily, there is a simple JUnit test (SentimentAnalysisTopologyTest) that executes the same topology locally.
You can check README for details. As for prerequisites, you can check my last post in order to install a single local HBase instance and a local Storm cluster with 2 Workers.
This is a very simplistic approach of how to use Apache Storm to perform sentiment analysis. I hope to have more free time to write a new post with a realistic solution for sentiment analysis.
Regards,
Adrianos Dadis.
—
Real Democracy requires Free Software